A Closer Look at ETL & Data Engineers
Simple always wins over complex. ELT and ETL pipelines should embody simplicity in conveying solutions to complex problems.


Table of contents
Data engineers are the unsung heroes in the world of data. They are responsible for building a passage for data within an organization based on the intended use case(s).
As simple as this explanation is, the reality of their demands isn't.
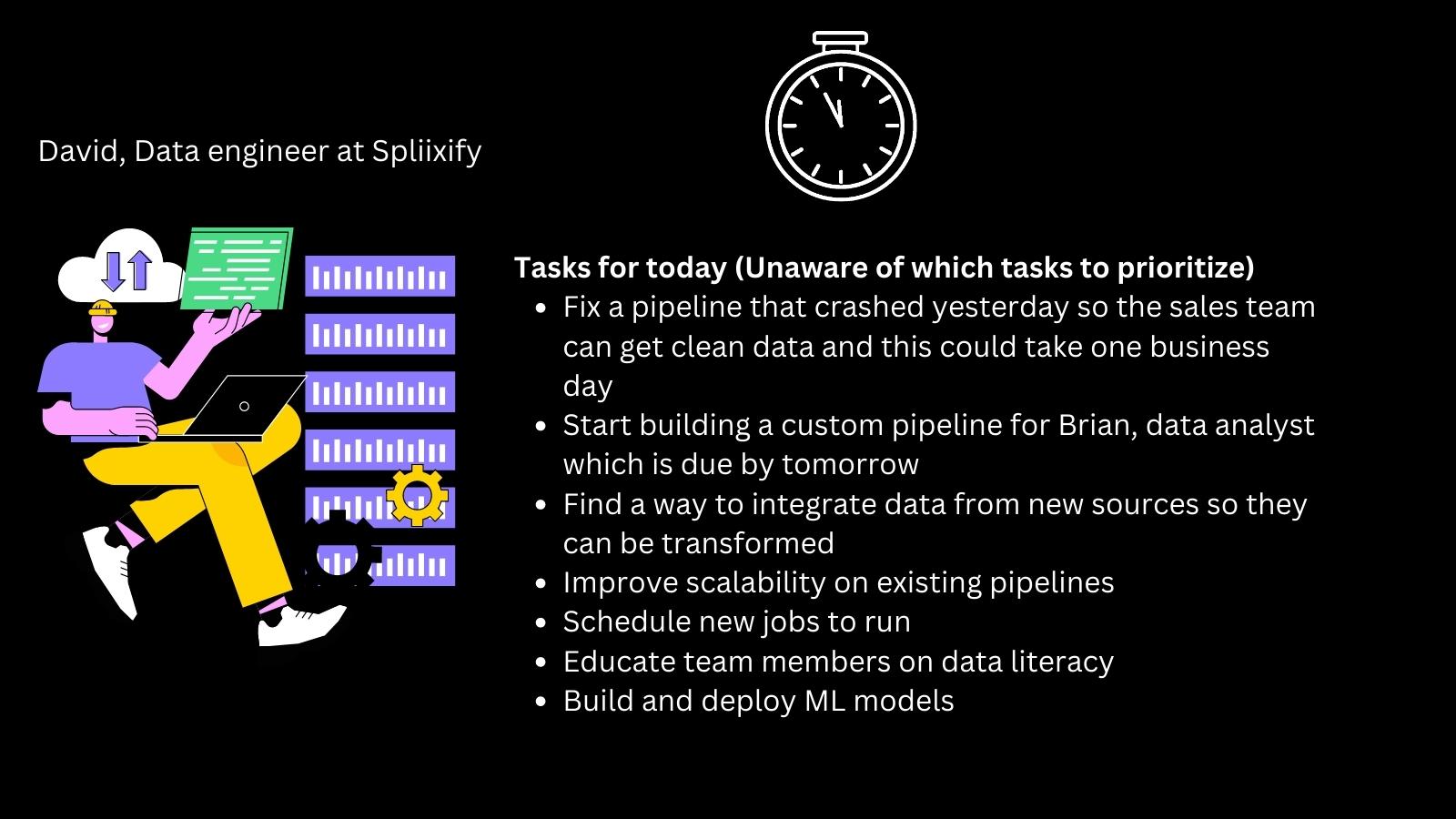
The image above largely depicts the challenges David faces as a data engineer in the simplest way possible.
Building and maintaining efficient ETL pipelines is not a simple task. More demanding, is that new business needs will warrant customized pipelines hence this challenge is not one-off.
As time goes by, improvements have been made to ease the routine of data engineers.
However, these improvements haven't completely erased the bottlenecks that these folks have to deal with. Maxime Beauchemin, a thought leader in data engineering, says this in the best way:
"As ETL pipelines grow in complexity, and as data teams grow in numbers, using methodologies that provide clarity isn’t a luxury, it’s a necessity".
So it then boils down to the subject matter of this piece. Drumrolls 🥁🥁🥁
What type of environment do data engineers need?
We've already established that tools exist for data engineers to work with in most cases, but some challenges remain a constant in the equation of creating a flow for data.
The contest now is on Complex Vs Simple. Yes, data engineers either way still get the job done but through the hassle. Employing a simple solution will get them out of the tight corner.
"**The ability to simplify means to eliminate the unnecessary so that the necessary may speak."**
- Hans Hofman
In line with Hans' thought, there is more that Necessary has to speak except when given the chance.
Amidst complexities, Data engineers need a simple environment that has:
- Seamless batch processing(Simple ETL)
Processing data in batches originally using ETL is a hectic task for data engineers. It is time-consuming, sometimes slow, difficult to fix, and most times, inefficient. In between all of this, there is a sudden pipeline crash and data engineers have to isolate the problem to fix and this could take more than one business day.
By using a simple ETL approach that simplifies batch processing, data engineers can enjoy the following benefits:
2. Reproducibility
" In order to be able to trust the data, the process by which results were obtained should be transparent and reproducible."
-Maxime Beauchemin
There has to be visible proof that data passed through specific processes to get to the next. Most ETL processes don't have such transparency and limit the trust in the already "transformed" data.
Simple in this case, showcases the data processes with ease and so much transparency that makes you trust the data when it is transformed. Also, the processes can be carried out again and still provide the same results and that makes it reproducible.
3. Job scheduling
Productivity for data engineers would mean juggling between multiple pipelines to oversee the running of their data jobs. While at this, errors could spring up and they have to troubleshoot it as well as make iterations for the next pipeline. Mind you, this takes hours!
This seems more like a circle that doesn't feel safe at any point.
Data engineers crave a better way to schedule their jobs. Rather than having to constantly oversee running pipelines which could be extremely boring by the way, automation can help them to pick times they want the batches to run and step back without interference.
4. Autoscaling and limitless ingestion
Spending so much time on ETL limits data engineers from integrating all the necessary data because of the fear of a sudden crash and this results in inefficient data models and biased reports from transformed data.
Data engineers need to enjoy a robust data pipeline environment where they can ingest as much data from anywhere without worries so they can scale efficiently.
5. Room for customizable workflows
Considering how complex ETL pipelines can be coupled with certain uncertainties of performance as well, it is preferable to transition to an environment that has built a robust ETL infrastructure and allows data engineers to customize pipelines based on needs per time efficiently.
This is also a plus because data engineers will not have to worry about maintaining the pipeline as that is fully covered by the vendor of the infrastructure so data engineers can focus on what's necessary with simple.
6. Data security
It’s important that the tools required for ETL are in line with compliance regulations to avoid the wrecking of an organization.
Most times, splitting data with various vendors for the ETL process can complicate issues by degrading data integrity and also putting data at risk of breach. Data engineers may doubt the quality of data after it has passed through many hands.
Handling all ELT processes in one place, limits such risk. Data engineers can easily track changes without sweating it out.
Simple wins over complex in aiding data engineers to carry out their work efficiently.